Coefficient of Variance
The coefficient of variance (CV) can be used to determine how much variance there is in the data. It allows us to compare the standard deviation to the average for the data set. Remember that you want have a small standard deviation for each data set, but sometimes having a small number for your standard deviation doesn't tell the whole story. Example: Say you have a standard deviation of +/- 0.1 g which is very low. But let's say your average for the data set is 0.3 g. Calculating the CV (see equation below) allows us to compare the S.D. to the average, and we find that the CV is 33%. This means the variance of the standard deviation is 33% of the average, which is a very high deviation. Thus, we can conclude the data in the data set is not very trustworthy...........in other words, there is a problem in the way we collected data or in how we performed the experiment that is not consistent!.
Remember: The higher the precision
of your data collection (the lower the % CV), the higher the likelihood that
there was no difference in the way each replicate/ individual test was performed. In other words, data within a data set which is collected
consistently should hypothetically have a Coefficient of Variance equal to zero
percent!
The value of determining the coefficient of variance is for noting whether
collection of some of the data for a particular data set may have had problems
or not!
Important:
Note that a team can have a low coefficient of variance for a set of data
(say 4% or better) which is highly desirable, and still they may not have accurate
test results. This means that they repeatedly made the
same mistake in collecting data. The team would have to create a graph
comparing the sampled data to the quality control data or they could calculate
percent deviation.
Calculating the Coefficient of Variance

Where s = standard deviation,
and 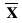 = mean (average).
= mean (average).
You can calculate the CV for the 3-5 replicates for a single
date's sampling.
The following table represents a table of one sample date's turbidity
data compared to the mean:
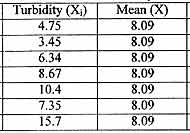
The standard deviation of the turbidity data has been calculated
to be 4.08. When the plugged into the coefficient of variance equation, we find:
CV (4.08 / 8.09) X 100 = 50.43 % .
The precision of the replicates was only 50.43 % which probably
means some of the data could be considered as outliers.
Note:
It helps to collect as much data as you can (usually 5 is a minimum
in serious testing) so that you can eliminate outliers and still have plenty
of data points to average.
Slichter